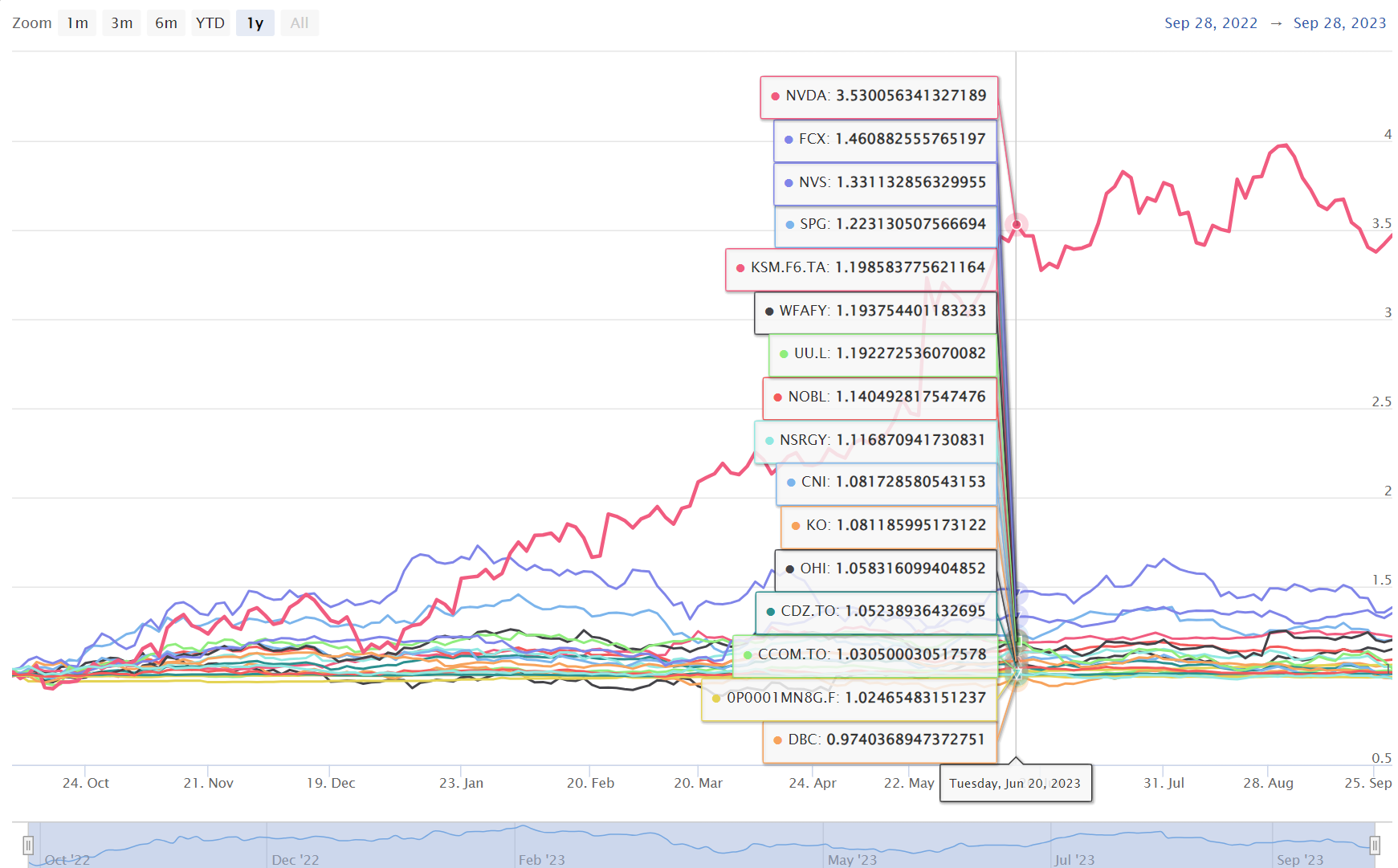
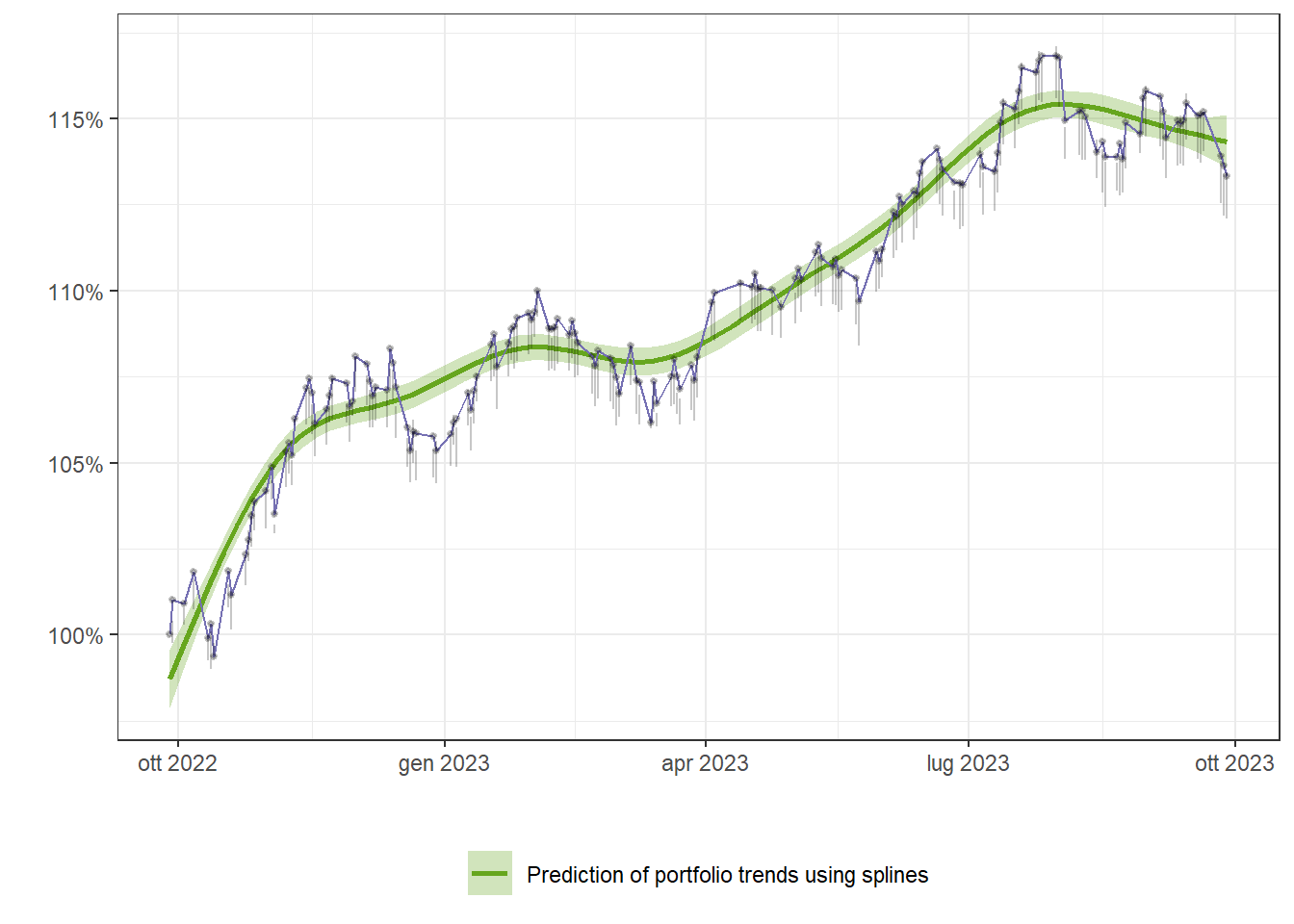
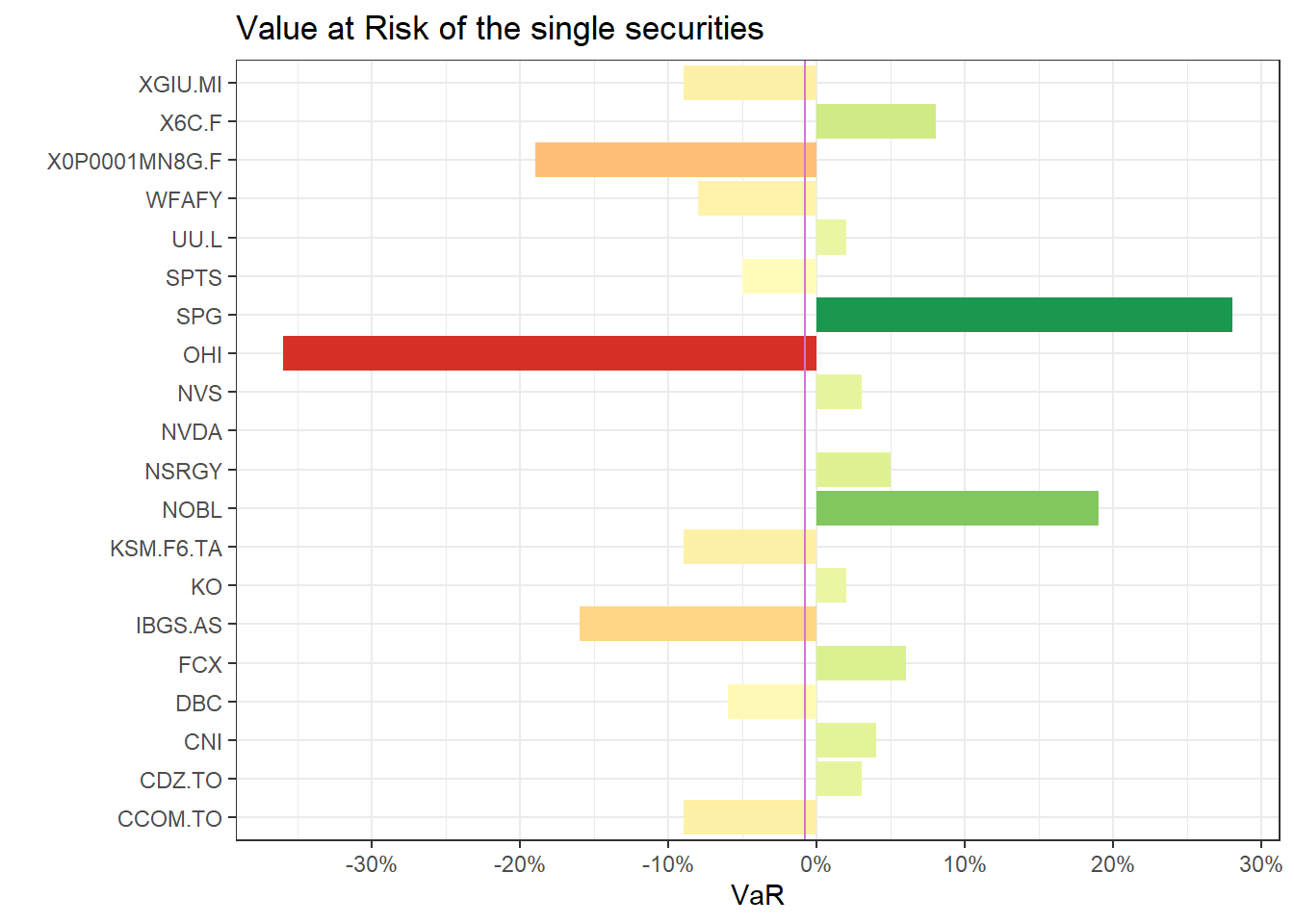
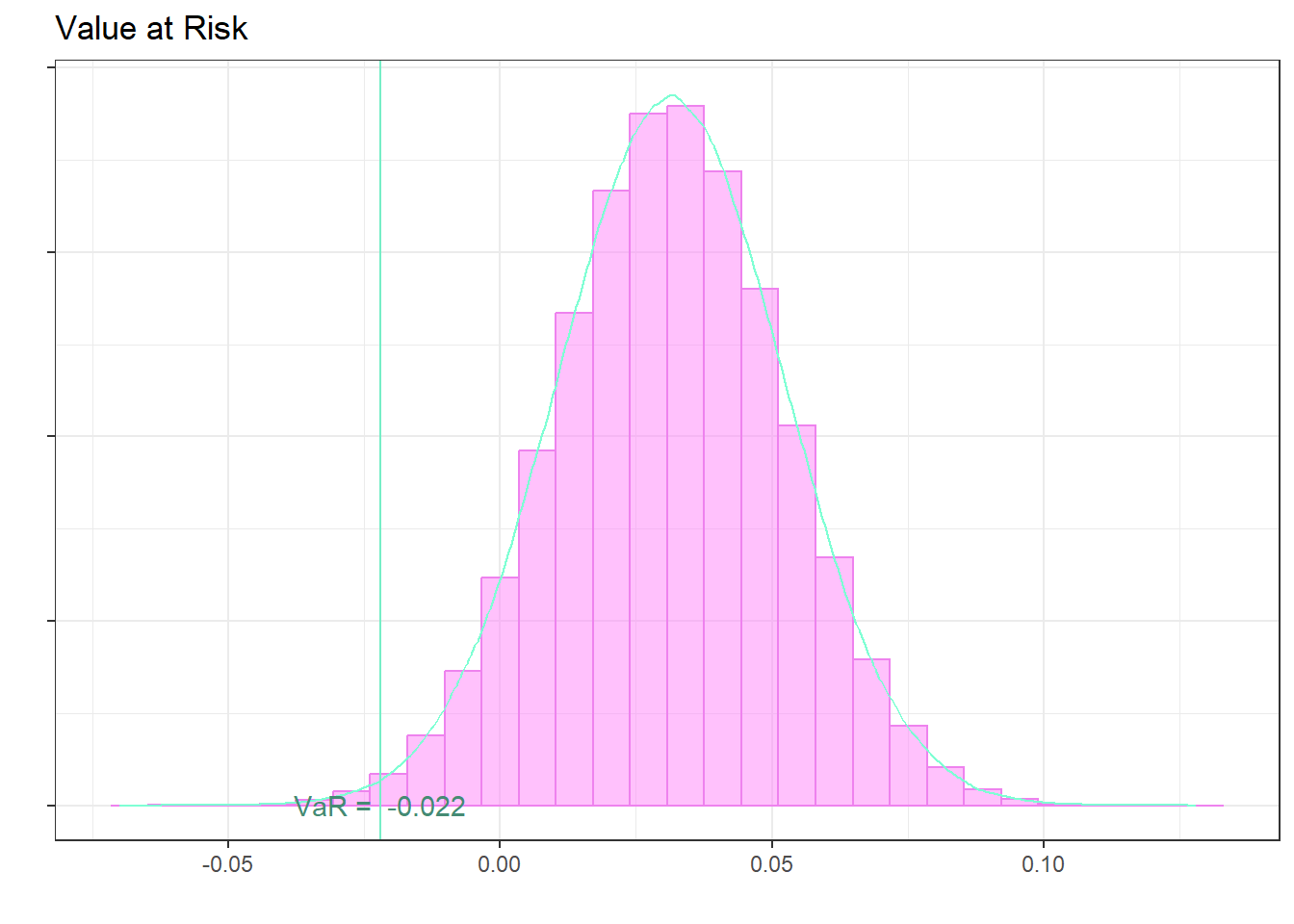
My aim was to find the best weights that could be used by a pension fund. The portfolio is composed by REITS, Commodities, CAT BOND, Dividends, Short term bonds, Cash and Inflation linked.
Import data
I built a dataset with tickers, categories and the initial weights of the portfolio.
Code
detailPortfolio =tibble(tickerList =c("SPG", # REITS"OHI","CCOM.TO", # Commodities"DBC","FCX","KSM-F6.TA","0P0001MN8G.F", # CAT BOND"CDZ.TO", # dividend"NOBL","NSRGY","CNI","WFAFY","UU.L","KO","NVS","NVDA", # nvidia no dividendi# short term bond -- in truth they are etfs that reproduce the trend# "SHY", # "VGSH","SPTS","IBGS.AS",# cash -- I placed a Canadian dollar future to represent liquidity"6C=F", "XGIU.MI"# Inflation linked ),category =c(rep("REITS",2),rep("Commodities",4),rep("CAT BOND",1),rep("Dividends",9),rep("Short term bonds",2),rep("Cash",1), rep("Inflation linked",1) ),weight =c( .08, .06, .046,# comodities .009, .01, .057, .07,# cat bond .02,# div .06, .02, .01, .017, .005, .005, .05, .023,# .07,# .07, .05, .128, .15,# .00, .13 ) )detailPortfolio |>summarise(across(weight, sum, na.rm =TRUE),.by = category ) |>gt() |>fmt_percent(vars(weight), decimals =1)
category
weight
REITS
14.0%
Commodities
12.2%
CAT BOND
7.0%
Dividends
21.0%
Short term bonds
17.8%
Cash
15.0%
Inflation linked
13.0%
Fixed Base Indices
Import data from Yahoo Finance for the last 5 years and construct the portfolio without the weights of each stock.
Code
stockData =lapply(detailPortfolio$tickerList, getSymbols,src ="yahoo",from =as.Date("2018-09-30"),to =as.Date("2023-09-29"),auto.assign = F )saveRDS(stockData, "data/stockData.rds")
Code
stockData =readRDS("data/stockData.rds")# fix tickets that have changed name during importdetailPortfolio |>mutate(tickerList =case_when( tickerList =="KSM-F6.TA"~"KSM.F6.TA", tickerList =="6C=F"~"X6C",TRUE~ tickerList ) ) -> detailPortfolio# compact the different listsnominalPortfolio =do.call(merge,stockData) %>%na.omit()# the CAT BOND is volume-freenominalPortfolio$X0P0001MN8G.F.Volume =1for(i in1:nrow(detailPortfolio)){ columnSelect = (!names(nominalPortfolio) %like%"Volume") &names(nominalPortfolio) %like% detailPortfolio$tickerList[i] nominalPortfolio[,columnSelect] = nominalPortfolio[,columnSelect] /rep(coredata(nominalPortfolio[1,columnSelect])[1],5) }as_tibble(nominalPortfolio)
The current portfolio has these indices, our goal now is to optimise the portfolio to maximise the sharpe rato index, i.e. to maximise the portfolio’s return while minimising its risk.
A simulation will be carried out using the MonteCarlo method where the experiment will be repeated by randomly extracting the weights, thus finding the best portfolio combination. In this case, the experiment will be repeated 5000 times but the portfolio weights will not be completely random, they will vary around the values we preset.
Code
set.seed(1)num_port =5000# Creating a matrix to store the weightsall_wts =matrix(nrow = num_port,ncol =nrow(detailPortfolio))# Creating an empty vector to store# Portfolio returnsport_returns =vector('numeric', length = num_port)# Creating an empty vector to store# Portfolio Standard deviationport_risk =vector('numeric', length = num_port)# Creating an empty vector to store# Portfolio Sharpe Ratiosharpe_ratio =vector('numeric', length = num_port)for (i inseq_along(port_returns)) { precisione =0.9 wts =sapply(1:length(weight), function(i) runif(1, precisione * weight[i], (2- precisione) * weight[i]))# wts = runif(length(tickerList)) wts = wts/sum(wts)# Storing weight in the matrix all_wts[i,] = wts# Portfolio returns port_ret =sum(wts * mean_ret)# port_ret <- ((port_ret + 1)^252) - 1# Storing Portfolio Returns values port_returns[i] = port_ret# Creating and storing portfolio risk port_sd =sqrt(t(wts) %*% (cov_mat %*% wts))# Più preciso ma ci mette troppo # port_sd = VaR(# R = return3mesi[, names(return3mesi) %like% "Adjusted"],# method = "historical",# portfolio_method = "component",# weights = wts# )$hVaR port_risk[i] = port_sd# Creating and storing Portfolio Sharpe Ratios# Assuming 0% Risk free rate sr = port_ret/port_sd sharpe_ratio[i] = sr}
Portfolio weights
The weights assigned by the portfolio with the highest sharpe ratio are shown in the interactive plot below.
Code
# Storing the values in the tableportfolio_values =tibble(Return = port_returns,Risk = port_risk,SharpeRatio = sharpe_ratio)# Converting matrix to a tibble and changing column namesall_wts = all_wts %>%data.frame() %>% tibblecolnames(all_wts) = detailPortfolio$tickerList# Combing all the values togetherportfolio_values =tibble(cbind(all_wts, portfolio_values))colnames(portfolio_values)[1:nrow(detailPortfolio)] = detailPortfolio$tickerListmin_var = portfolio_values[which.min(portfolio_values$Risk),]max_sr = portfolio_values[which.max(portfolio_values$SharpeRatio),]# weightOLD = weightweight = max_sr[,1:nrow(detailPortfolio)] %>%as.numeric() %>%round(4) # con l'arrotondamento potrebbe non fare 1 e lo calibro con il primo titolo, # ciò non influenzerà significativamente sullo scostamento del portafoglioweight[1] = weight[1] +1-sum(weight)# max_sr %>% # t() %>%# data.frame()p = max_sr %>%gather(detailPortfolio$tickerList, key = Asset,value = Weights) %>%cbind(Category =factor(detailPortfolio$category)) %>%mutate(Asset = Asset %>%as.factor() %>%fct_reorder(Weights),Percentage =str_c(round(Weights*100,2), "%")) %>%ggplot(aes(x = Asset,y = Weights,fill = Category,label = Percentage)) +geom_bar(stat ='identity') +geom_label(nudge_y = .01, size =3) +theme_minimal() +labs(x ='Tickers',y ='Weights',title ="Weights of the portfolio tangent to the efficient frontier") +scale_y_continuous(labels = scales::percent) +guides(fill =guide_legend(override.aes =aes(label =""))) +theme(legend.position ="bottom") +coord_flip()ggplotly(p)
Efficient frontier
The graph below shows the values of the portfolios created during the optimisation process. The red dot represents the portfolio with the highest sharpe ratio.
Code
p = portfolio_values %>%ggplot(aes(x = Risk, y = Return, color = SharpeRatio)) +geom_point() +theme_classic() +scale_y_continuous(labels = scales::percent) +scale_x_continuous(labels = scales::percent) +labs(x ='Annual risk',y ='Annual return',title ="Portfolio optimization and efficient frontier") +geom_point(aes(x = Risk,y = Return),data = max_sr,color ='darkred') ggplotly(p)
In the following graph, the different securities are shown with their yield, their variance on the abscissa and are coloured according to their coefficient of variation. This graph helps in the choice of initial weights (pre-optimisation) as it is easy to visualise those that perform best.
Code
returnTicker =map_dfc( detailPortfolio$tickerList,~dailyReturn(Cl(nominalPortfolio[,names(portfolio) %like% .x])) )colnames(returnTicker) = detailPortfolio$tickerListreturnTickerIndici = returnTicker %>%as.tibble() %>%summarise_all(sum) %>%pivot_longer(1:nrow(detailPortfolio),names_to ="Titoli",values_to ="Rendimento" ) %>%add_column(returnTicker %>%as.tibble() %>%summarise_all(sd) %>%pivot_longer(1:nrow(detailPortfolio),names_to ="Titoli",values_to ="Varianza" ) %>% dplyr::select(Varianza) ) %>%mutate(Variazione =ifelse(round(Rendimento, 2) !=0, Varianza/abs(Rendimento),1)) hValMin =1.8# giocando con questo parametro si cambia l'asse delle y# modificando la distanza dei punti estremi ai punti centralihValMax =1p = returnTickerIndici %>%mutate(quantili =punif(Rendimento,min = hValMin *min(Rendimento), # se non metto hvalmin# il min di Rendimento vale 0 e di conseguenza il log# tende a meno infinitomax = hValMax *max(Rendimento),log.p = T), across(where(is.numeric), \(x) round(x, 4)),# across(vars(Rendimento), ) ) |>ggplot(aes(y = quantili,x = Varianza,color = Variazione,label = Titoli,z = Rendimento #serve solo per l'etichetta nel grafico interattivo )) +geom_point(size =1.5) +scale_color_distiller(palette ="RdYlGn", direction =-1) +scale_x_log10(labels = scales::percent_format(accuracy = .2),breaks = scales::breaks_log(n =10, base =10)) +scale_y_continuous(labels =function(x) scales::percent(qunif(x,min = hValMin *min(returnTickerIndici$Rendimento),max = hValMax *max(returnTickerIndici$Rendimento),# associo i valori originali invertendo la funzione di ripartizionelog.p = T), scale =1 ),breaks = scales::pretty_breaks(10)) +labs(x ="Variation", y ="Return", color ="Coefficient \nof variation") +theme(legend.position ="right", legend.title.align =0) ggplotly(p, tooltip =c("z", "x", "color", "label"))
Code
return3mesi = nominalPortfolio %>% CalculateReturns %>%to.period.contributions("quarters")weight_max_sr = max_sr %>%t() %>%head(nrow(detailPortfolio)) %>%as.vector()VaR(return3mesi[,names(return3mesi) %like%"Open"],method ="historical",weights = weight_max_sr,portfolio_method ="marginal") %>%pivot_longer(1:length(weight_max_sr) +1,names_to ="Titoli",values_to ="VaR") %>%mutate(VaR =round(VaR *100, 2)) %>%ggplot(aes(x = Titoli, y = VaR, fill = VaR)) +geom_col() +geom_hline(aes(yintercept = PortfolioVaR), color ="orchid") +coord_flip() +scale_fill_distiller(palette ="RdYlGn", direction =1) +theme(legend.position ="none") +scale_x_discrete(labels =function(x) str_remove(x,".Open")) +labs(x ="",title ="Value at Risk of the single securities", ) +scale_y_continuous(labels = scales::percent_format(),breaks = scales::pretty_breaks(8))
The following histogram shows the simulation of 1000000 samples taken from a normal of mean equal to the portfolio return on a four-monthly basis and the variance equal to the portfolio variance on a four-monthly basis.